
TensorFlow - not another introduction II
- 4 minsBackground
In this post, we will introduce a more interesting, state-of-art neural network model to the readers: Long-short-term-memory Network.
Long-short-term-memory network or LSTM network for short is a special case in Recurrent Neural Network that tries to avoid the “vanishing gradient problem.”
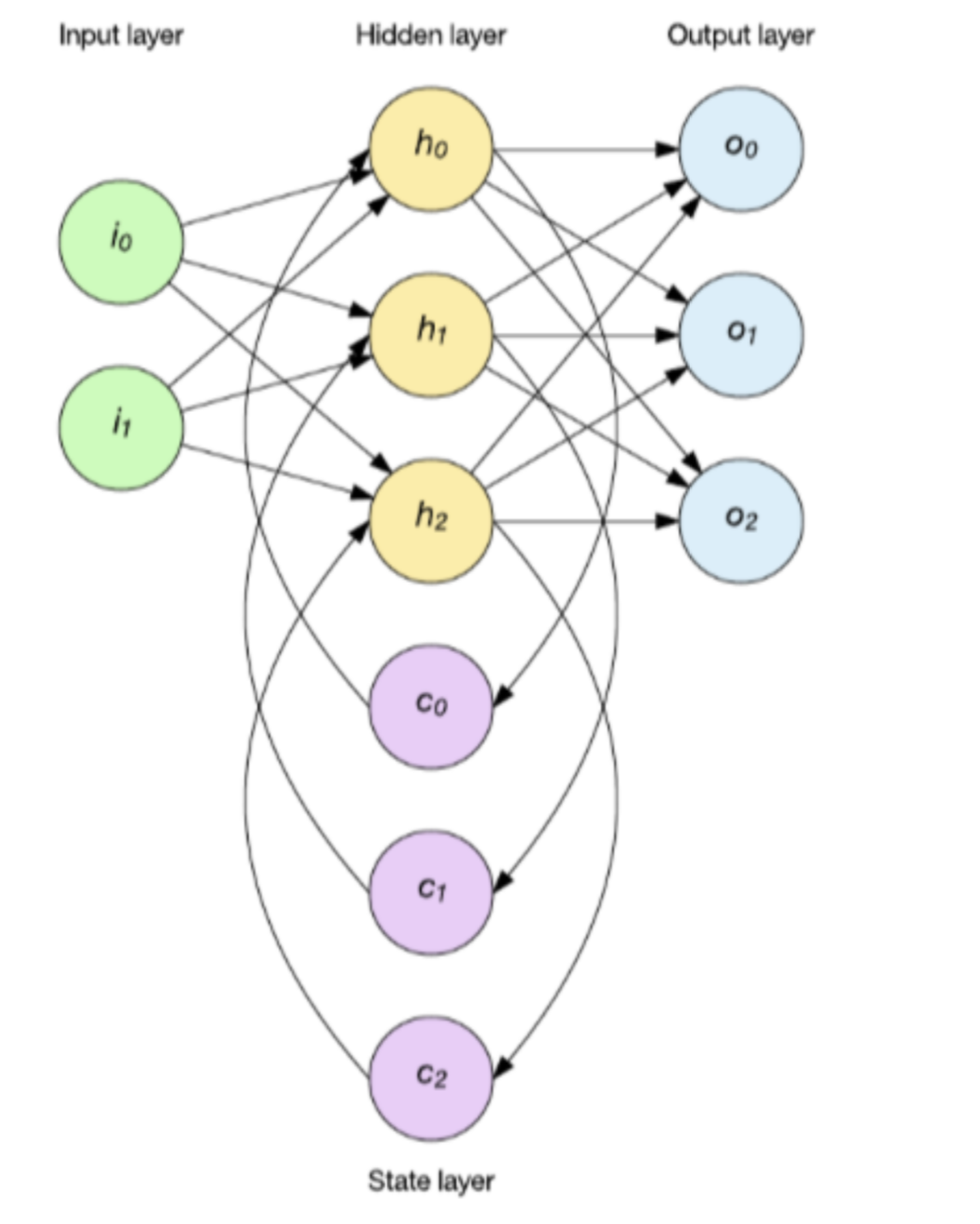
Lost in the jargons? Let’s take a step back and try to understand all the words in the above paragraph. Recurrent Neural Network is a type of neural network that specializes in processing sequences of inputs via its storage of the internal states.
A typical Recurrent Neural Network looks like the following.
Vanishing Gradient Problem
If we unroll the network above, we will see something like this, 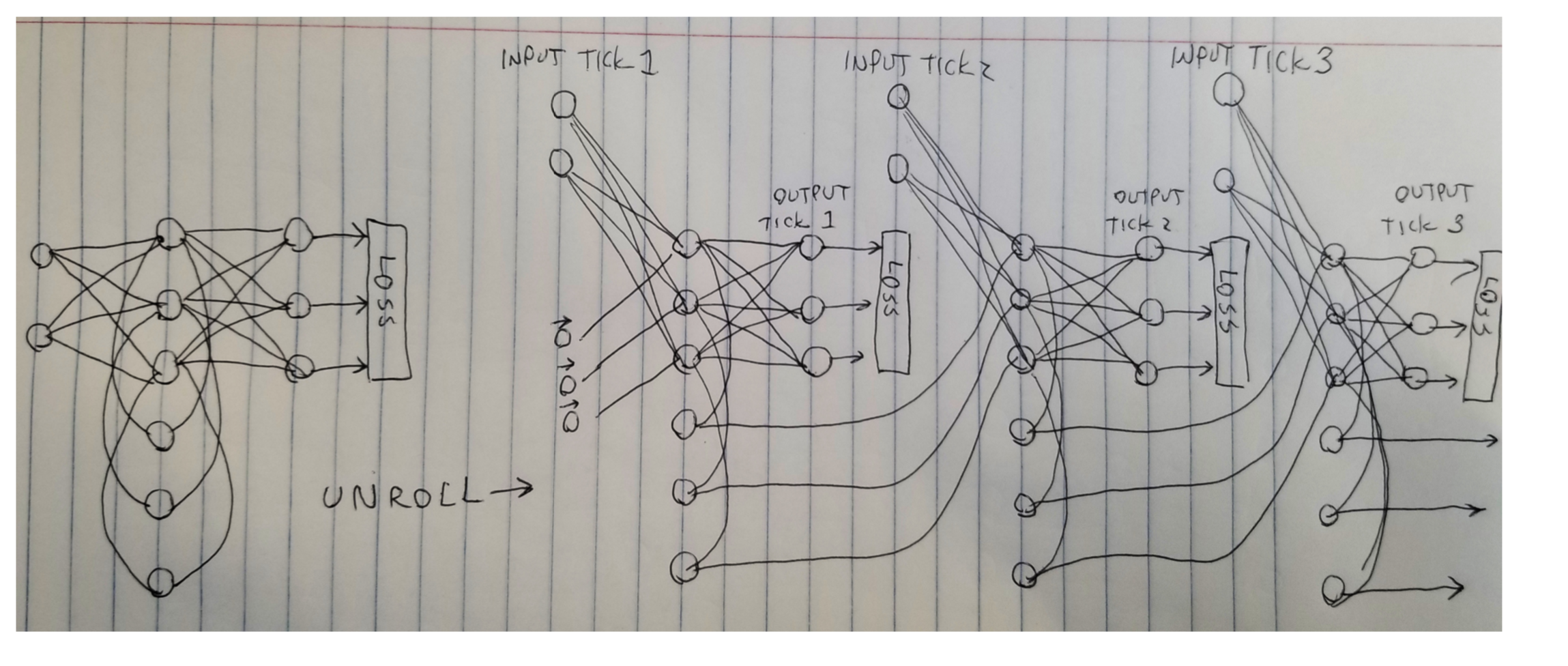
Recall how we calculate the derivative in the backpropagation from an early post.
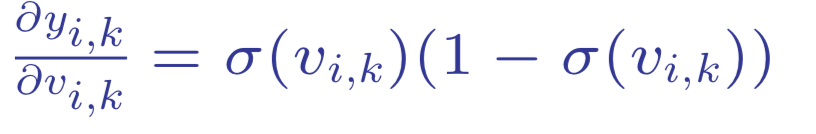
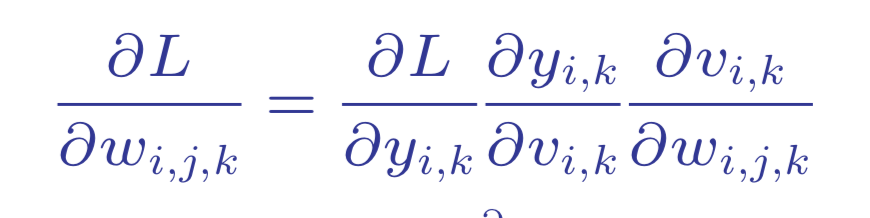
Note that the derivative of loss with respect to activation function is often less than 1.
Think about the derivative with respect to the logistic function on the left for example, we know that maximum value is reached when the activation function takes the value of 0.5 which is less than 1.
If we have a deep RNN and apply that multiplier constantly as we backpropagate the errors to the input layer, the derived gradient is approaching zero.
The error from the output layer may not be able to influence the upfront layers as they are too far.
This pattern would make the training stagnant as no correction would be made in the upfront layers due to the errors in the output.
You can see more detailed explanations of the vanishing gradient problem below.
LSTM
LSTM Module
Walla! Here comes the savior – LSTM network. In LSTM net, we don’t push the long term memory through the activation function, i.e. we don’t backpropagate the long term memory of an error all the way to the input layer. Thus, we don’t have a vanishing gradient problem!
Let’s look at the LSTM “modules” as below.
In the module,
- Vector travels along the lines
- A circle/oval represents applications of a function to each dimension in a vector
- A rectangle represents a neural network
- 𝞂 stands for a logistic activation layer at the top
- tanh means a hyperbolic tangent activation layer at the top
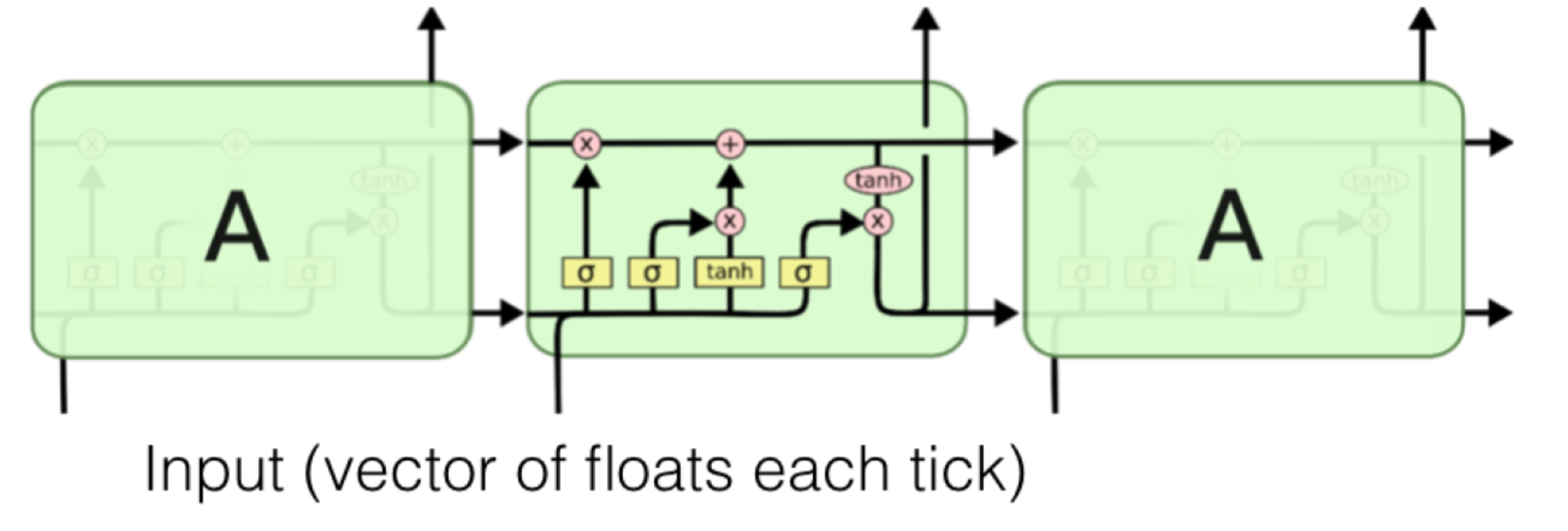
Note that each module accepts input at a particular time tick as well as state(“long term memory”) and last output(“short term memory”). Then the module will use all of them to output a view of its current state.
A Single LSTM Unit
A single LSTM unit looks like this,
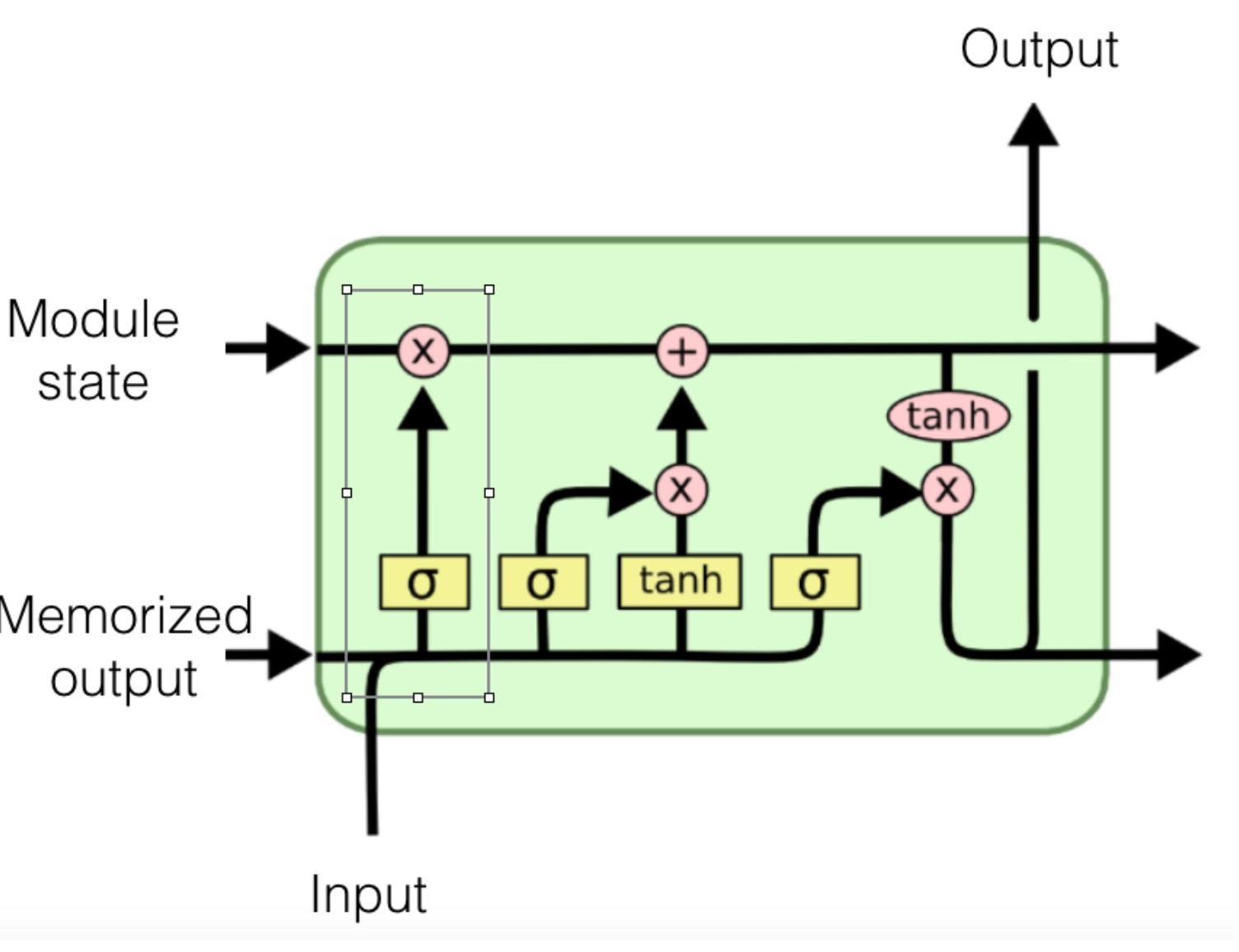
First we will run teh "forget gate",
- Last output and new input pass through a neural net with logistic layer at the top
- it will produce all values from 0 to 1
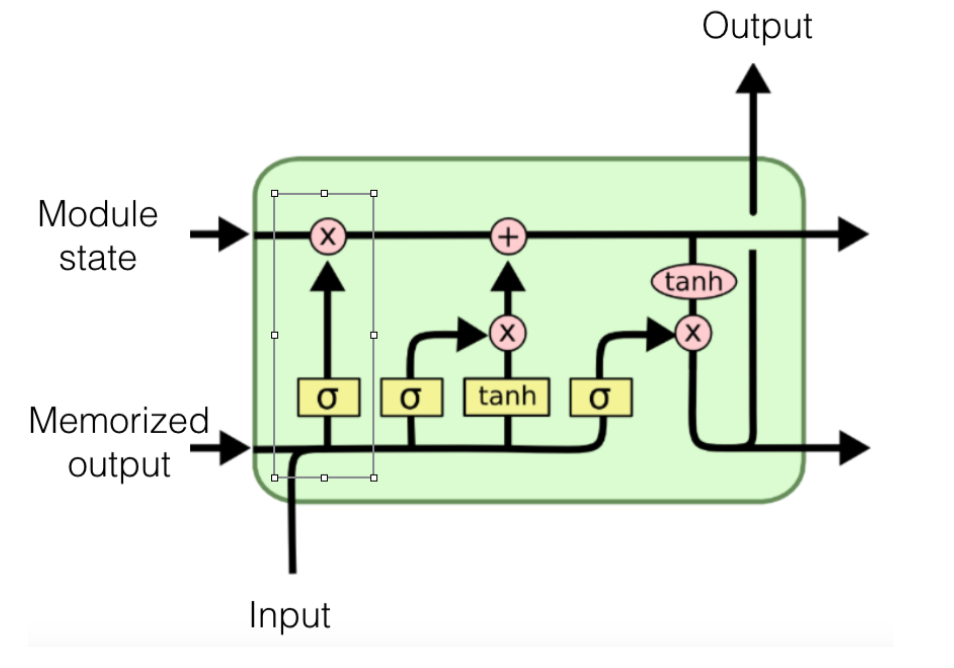
Then we run an "input gate",
- Input plus last output passes through two NNs
- One with a tanh layer at the top producing a value from -1 to 1
- One with logistic layer at the top producing a value from 0 to 1
- Item-by-item multiplication will produce a vector for the current state
- The update is added to the long-term memory
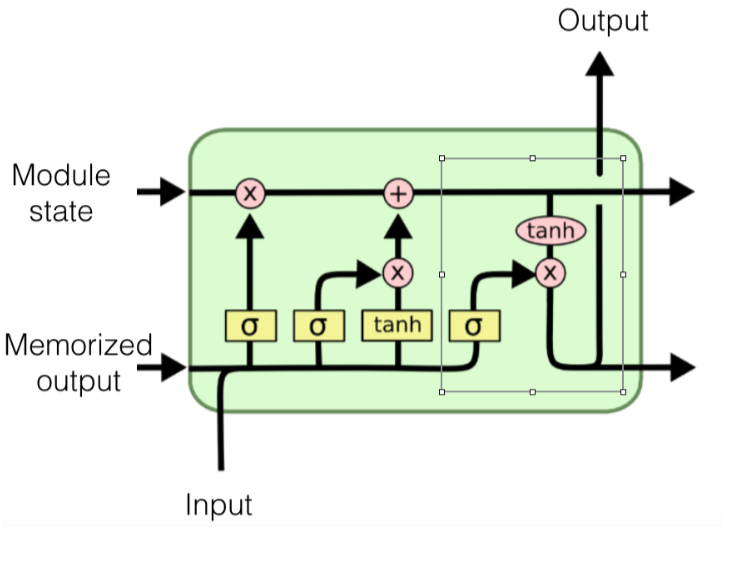
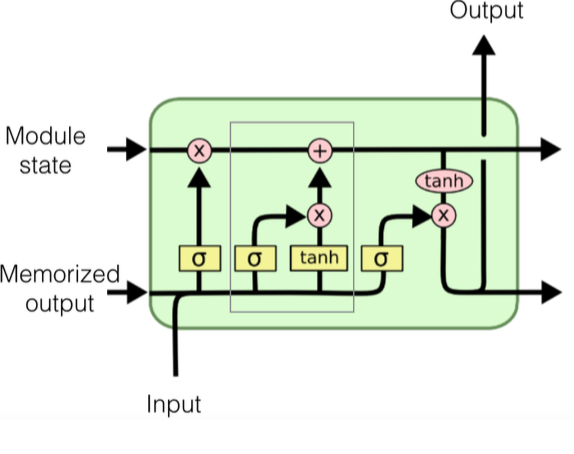
In the end, we run "output gate",
- Push state through a tanh layer at the top producing a value from -1 to 1
Code Snippets
With the help of Tensorflow framework, creating an LSTM unit is quite straightforward.
Let’s take a brief walk-through.
Set up a 1000-unit LSTM network.
hiddenUniots = 1000
lstm = tf.nn.rnn_cell.LSTMCell(hiddenUnits)
Set up the initial state
initialState = lstm.zero_state(batchSize, tf.float32)
Train the LSTM net
currentState = initialState
for iter in range(maxSeqLen):
timeTick = input[iter]
# concatenate the state with the input,
# then compute the next state
(lstm_output, currentState) = lstm(timeTick, currentState)
where input is your stacked input variables.
Note that lstm_output is your final output, you can do a feedforward or softmax afterward to regularize it.
And…, that’s it.
Within five lines you could set up an LSTM module and you can choose optimizer to train the model(how to do that? check out the TensorFlow Tutorial Post)
More About LSTM
If you wanna know more about LSTM, check out the following